Using SQL to interface with Google Analytics data stored on Amazon S3
Introduction
In the realm of web analytics, Google’s presence remains formidable. And it’s no surprise—as a free service with a brain-dead easy setup and a wide range of collected user information, Google Analytics has a lot going for it. But if you’d like to move away from the standard Analytics web interface, what are your options? The intended audience for this article is those who might wish for a little more flexibility with their Google Analytics data.
An excellent tool for accomplishing this flexibility is Apache Drill. Drill is a piece of open source software that’s capable of providing a standard SQL command-line interface to a wide range of data types stored in a variety of ways. In this application we’ll be using Drill to talk to some JSON data retrieved using the Google Analytics API and stored on Amazon S3.
Accessing the Google Analytics API from Python
Google Analytics can be interfaced via a number of different languages, but in this example we’ll constrain ourselves
to the Python API. The necessary files are easily installed via the Python package manager pip on the command line:
$ sudo pip install --upgrade google-api-python-client
The next step is to generate the credentials necessary to use the Google Analytics API from within a script. To do this log in to console.developers.google.com and create a new project. With your new project selected we need to first enable the Analytics API. Click on “APIs” under “APIs & auth”, and then select “Analytics API” in the “Advertising APIs” grouping. In the page that shows up next, click “Enable API.” Now it’s time to go to “Credentials” on the left column, and click “Add credentials.” Select “Service account” from the drop down, and “P12” before hitting the “Create” button.
This action will download a .p12 file to your computer that we’ll need later for the script, and then forward you to a
page with a listing of your service accounts. The email address you see in the left column will need to be added to your
Google Analytics settings. Head over to analytics.google.com, click “Admin” at the top, select
“User Management” from the left, and then paste the email address you saw listed for your service account into the “Add
permissions for:” box. From here just click “Add” and you’re done doing the web configuration necessary for making
Google Analytics to work with a script.
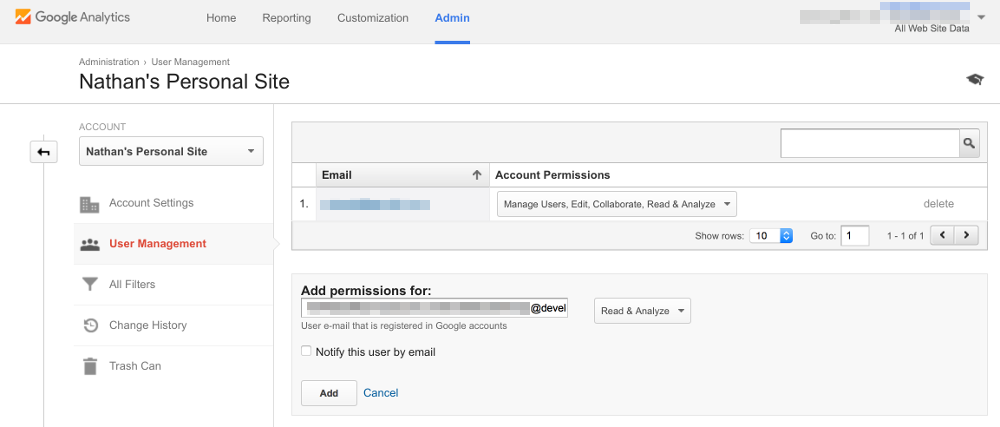
You need to add the email associated with your service account to your Google Analytics in order to enable API access from the script.
Using Amazon S3 from Python
The example script included in this article will do a couple different things: First, it exposes a specified set of
Google Analytics data as a dump to a JSON file, and second, it uploads this dumped data to the cloud by way of Amazon
S3. In order for this second task to succeed, we also to need to ensure that the script has access to the necessary
Amazon Web Services credentials by going to console.aws.amazon.com/iam/home. On this
page click “Users” on the left, and then select your username from the list that shows up. Then scroll down to the
“Security Credentials” section and click the button that says “Create Access Key.” Next hit “Download Credentials” to
retrieve a file called credentials.csv. The values from this file need to be placed in ~/.aws/credentials in the
following way:
[default]
aws_access_key_id = ACCESSKEYID_FROM_CREDENTIALS_CSV
aws_secret_access_key = SECRETACCESSKEY_FROM_CREDENTIALS_CSV
Finally, you’ll need to install the Python package necessary to access your S3 storage via a script:
pip install boto3
Example Python script for dumping Google Analytics to S3
Now we’re finally ready to take a look at the example script, which I’ve called ga_dump.py:
# Portions of this code are based heavily on Google's HelloAnalytics.py exmaple:
# https://developers.google.com/analytics/devguides/reporting/core/v3/quickstart/service-py
# As such, this software is covered under the Apache 2.0 License:
# http://www.apache.org/licenses/LICENSE-2.0
import httplib2
import sys
import json
import boto3
from apiclient.discovery import build
from oauth2client import client, file, tools
from oauth2client.client import SignedJwtAssertionCredentials
# Global variables that hold information relevant to your GA access
ga_key_file_name = "PATH TO YOUR .p12 KEY FILE FROM DEV CONSOLE"
ga_service_email = "SERVICE EMAIL CREATED IN DEV CONSOLE"
# Global variable that holds the name of the S3 bucket that you're dumping to
my_s3_bucket_name = "NAME OF YOUR AMAZON S3 BUCKET"
# Create a service
def get_ga_service():
print("\nConnecting to Google Analytics...\n")
f = open(ga_key_file_name, 'rb')
ga_key = f.read()
f.close()
ga_credentials = SignedJwtAssertionCredentials(ga_service_email, ga_key, scope=['https://www.googleapis.com/auth/analytics.readonly'])
ga_api_name = 'analytics'
ga_version = 'v3'
ga_service = build(ga_api_name,ga_version, http=ga_credentials.authorize(httplib2.Http()))
return ga_service
# Get a profile id from the service
# By default gets the id for the the first account, property, and view
def get_ga_id(ga_service, acc_num = 0, prop_num = 0, view_num = 0):
print("Using the following settings:\n")
try:
acc = ga_service.management().accounts().list().execute().get('items')[acc_num]
acc_id = acc.get('id')
print("Google Analytics account: " + acc.get('name'))
except:
print("Error finding account")
return None
try:
prop = ga_service.management().webproperties().list(accountId=acc_id).execute().get('items')[prop_num]
prop_id = prop.get('id')
print("Property name: " + prop.get('name'))
except:
print("Error finding property")
return None
try:
view = ga_service.management().profiles().list(accountId=acc_id,webPropertyId=prop_id).execute().get('items')[view_num]
view_id = view.get('id')
print("Analytics view name: " + view.get('name') +"\n")
except:
print("Error finding view")
return None
return view_id
def pretty_json(obj):
return json.dumps(obj, sort_keys=True, separators=(',',':'), indent=4)
# Dumps to three files:
# One for geographic (geo) data, one for data about acquisition (acq), and another about devices used (ev)
def fetch_and_dump(ga_service,ga_id):
# Google Analytics metrics we want
ga_metrics = 'ga:users,\
ga:newusers,\
ga:sessions,\
ga:bounces,\
ga:sessionDuration,\
ga:hits'
dims_date = ',ga:date,ga:hour'
# Sets of dimensions to look at
ga_dims_geo = 'ga:country,\
ga:region,\
ga:city,\
ga:continent,\
ga:language'+dims_date
ga_dims_acq = 'ga:source,\
ga:medium,\
ga:socialNetwork'+dims_date
ga_dims_dev = 'ga:browser,\
ga:browserVersion,\
ga:screenResolution,\
ga:deviceCategory'+dims_date
data_geo = ga_service.data().ga().get(ids='ga:'+ga_id,start_date=sys.argv[1], end_date=sys.argv[1], metrics=ga_metrics, dimensions=ga_dims_geo).execute()
data_acq = ga_service.data().ga().get(ids='ga:'+ga_id,start_date=sys.argv[1], end_date=sys.argv[1], metrics=ga_metrics, dimensions=ga_dims_acq).execute()
data_dev = ga_service.data().ga().get(ids='ga:'+ga_id,start_date=sys.argv[1], end_date=sys.argv[1], metrics=ga_metrics, dimensions=ga_dims_dev).execute()
file_geo = 'google_analytics_geo_'+sys.argv[1]+'.json'
file_acq = 'google_analytics_acq_'+sys.argv[1]+'.json'
file_dev = 'google_analytics_dev_'+sys.argv[1]+'.json'
f_geo = open(file_geo,'w')
f_acq = open(file_acq,'w')
f_dev = open(file_dev,'w')
f_geo.write(pretty_json(data_geo))
f_acq.write(pretty_json(data_acq))
f_dev.write(pretty_json(data_dev))
f_geo.close()
f_acq.close()
f_dev.close()
# return a list of the dump files
file_list = [file_geo, file_acq, file_dev]
return file_list
# Upload dumped files to Amazon cloud storage
def upload_to_s3(file_list):
aws_s3 = boto3.resource('s3')
# Make a bucket if we need to
aws_s3.create_bucket(Bucket=my_s3_bucket_name)
for file_name in file_list:
aws_s3.Bucket(my_s3_bucket_name).put_object(Key=file_name, Body = open(file_name, 'rb'))
# Main program execution
my_service = get_ga_service()
if my_service == None:
print("Error connecting to Google Analytics!")
else:
my_id = get_ga_id(my_service)
print("Dumping Analytics data to files...")
files = fetch_and_dump(my_service,my_id)
print("Done!")
print("\nUploading to Amazon S3 storage...")
upload_to_s3(files)
print("Done!")
The script takes a single command line argument: an ISO 8601 formatted date that specifies which day to dump Google Analytics data from. For instance to retrieve the previous day’s data, you could run:
$ python ga-dump.py `date -v -1d "+%Y-%m-%d"`
One possible use case would involve running this command at regular intervals via the unix cron daemon. As written, the script outputs three JSON files: one for visitor geographic data, one for visitor acquisition data, and one for data about the kinds of devices visitors are using.
Before running, don’t forget to change the global variables at the top of the listing to match your Google Analytics credentials and S3 bucketname! (Also: users of OS X will need to implement this fix before the script can run).
Setting up Apache Drill for use with S3
Now that we can toss dumps of Google Analytics up to the AWS cloud without much effort, it’s time to implement Drill as an SQL interface to the data. Installing Drill itself is an extremely simple process (all you need is Java and the Drill tarball), but we’ll need to do a little configuration in order to talk to our S3 bucket.
First, edit the file core-site.xml in the ./conf directory of the Drill install, replacing the relevant parts with
your Amazon S3 credentials:
<configuration>
<property>
<name>fs.s3a.access.key</name>
<value>ENTER_YOUR_ACCESSKEY</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>ENTER_YOUR_SECRETKEY</value>
</property>
</configuration>
Next, start up the embdedded (single machine) version of Drill
~/apache-drill/bin/drill-embedded
so we can use the Drill Web Console located at http://localhost:8047. We’ll proceed by making a copy of the ‘dfs’
storage plugin. To do this go to the 'Storage’ page, and hit 'Update’ next to 'dfs’, making a copy of the text
listed in the “Configuration” box that’s displayed on the next page. Now type a name for our new S3 plugin into the “New
Storage Plugin” box at the bottom of the previous page (“s3-ga” might make a good choice). Place the text for the 'dfs’
plugin into the box, editing "connection": "file:///" so that it specifies S3 and the name of your bucket instead, as
in "connection": "s3a://example.bucketname". Hit “Create” to make the plugin.
Querying Google Analytics JSON with Apache Drill
Now we’re ready to start querying our Google Analytics JSON using Drill! Try a simple SELECT * from the drill-embedded prompt:
> SELECT * FROM `s3-ga`.`google_analytics_geo_2015-10-19.json`;
You may notice that the results of this query are not exactly… beautiful. This is because the structure of a Google Analytics JSON dump isn’t compatible with simple queries like this. And that’s okay! We can easily work around that with some slightly more sophisticated SQL (Hey, if you wanted easy you’d be using the web interface, right?).
To list information about the columns of our data set, we can use the following command:
> SELECT ROW_NUMBER() OVER(ORDER BY 1) - 1 AS `Column Index`, KVGEN(FLATTEN(ga_table.columnHeaders))[2] AS `Column Info`
> FROM `s3-ga`.`google_analytics_geo_2015-10-19.json` ga_table;
+---------------+----------------------------------------------+
| Column Index | Column Info |
+---------------+----------------------------------------------+
| 0 | {"key":"name","value":"ga:country"} |
| 1 | {"key":"name","value":"ga:region"} |
| 2 | {"key":"name","value":"ga:city"} |
| 3 | {"key":"name","value":"ga:continent"} |
| 4 | {"key":"name","value":"ga:language"} |
| 5 | {"key":"name","value":"ga:date"} |
| 6 | {"key":"name","value":"ga:hour"} |
| 7 | {"key":"name","value":"ga:users"} |
| 8 | {"key":"name","value":"ga:newusers"} |
| 9 | {"key":"name","value":"ga:sessions"} |
| 10 | {"key":"name","value":"ga:bounces"} |
| 11 | {"key":"name","value":"ga:sessionDuration"} |
| 12 | {"key":"name","value":"ga:hits"} |
+---------------+----------------------------------------------+
13 rows selected (1.739 seconds)
And now that we know the column index for 'ga:city’ is '2’ we can use this query to inspect what cities visitors came from on the date of the file:
> SELECT DISTINCT FLATTEN(ga_table.`rows`)[2] AS Cities FROM `s3-ga`.`google_analytics_geo_2015-10-19.json` ga_table;
+-------------+
| Cities |
+-------------+
| (not set) |
| Almaty |
| Pushkino |
| Samara |
| Seoul |
| Tolyatti |
| Tula |
| Volgodonsk |
+-------------+
8 rows selected (1.292 seconds)
This simple example is fine, but as I pointed out before the advantage of this approach is the flexibility you gain in making queries. So let’s set our sights on doing something that’s impossible to accomplish even in the 'Custom Reports’ interface of the Google Analytics web GUI: inspecting more than 5 analysis dimensions simultaneously.
The following statement asks for the total number of sessions along the dimensions of date, hour, browser name, browser version, screen resolution, and type of device. Formulating a statement that analyzes several columns of data is somewhat more complicated than our previous single-column example, and I ended up constructing mine out of two subqueries:
SELECT `Date`, `Hour`, Browser, Version, Resolution, Device, SUM(CAST(Sessions AS INTEGER)) `Total Sessions`
FROM (SELECT data[4] `Date`, data[5] `Hour`, data[0] Browser, data[1] Version, data[2] Resolution, data[3] Device, data[8] Sessions
FROM (SELECT FLATTEN(ga_table.`rows`) data
FROM `s3-ga`.`google_analytics_dev_2015-10-19.json` ga_table))
GROUP BY `Date`, `Hour`, Browser, Version, Resolution, Device
ORDER BY `Date`, `Hour`;
Here the innermost query FLATTENs the data while the next one picks out columns and assigns them names. The main query handles tallying the total sessions and organizing the data.
Unfortunately my personal site doesn’t get enough traffic to take advantage of the GROUP BY, but the results look like this:
+-----------+-------+------------+-----------------+-------------+----------+-----------------+
| Date | Hour | Browser | Version | Resolution | Device | Total Sessions |
+-----------+-------+------------+-----------------+-------------+----------+-----------------+
| 20151019 | 03 | Safari | 8.0 | 1366x768 | mobile | 1 |
| 20151019 | 04 | YaBrowser | 44.0.2403.3043 | 1024x768 | desktop | 1 |
| 20151019 | 04 | Chrome | 40.0.2214.111 | (not set) | desktop | 2 |
| 20151019 | 05 | YaBrowser | 44.0.2403.3043 | 1024x768 | desktop | 1 |
| 20151019 | 07 | Safari | 8.0 | 1366x768 | mobile | 1 |
| 20151019 | 10 | Chrome | 39.0.2171.71 | 1024x768 | desktop | 1 |
| 20151019 | 10 | Safari | 8.0 | 1366x768 | mobile | 1 |
| 20151019 | 11 | Safari | 8.0 | 1366x768 | mobile | 1 |
| 20151019 | 12 | Safari | 8.0 | 1366x768 | mobile | 0 |
| 20151019 | 12 | Chrome | 46.0.2490.71 | 1024x768 | desktop | 1 |
| 20151019 | 13 | Safari | 8.0 | 1366x768 | mobile | 1 |
| 20151019 | 14 | Safari | 8.0 | 1366x768 | mobile | 1 |
| 20151019 | 15 | Safari | 8.0 | 1366x768 | mobile | 1 |
| 20151019 | 16 | Safari | 8.0 | 1366x768 | mobile | 1 |
| 20151019 | 18 | Safari | 8.0 | 1366x768 | mobile | 1 |
| 20151019 | 19 | Safari | 8.0 | 1366x768 | mobile | 1 |
| 20151019 | 21 | Safari | 8.0 | 1366x768 | mobile | 2 |
| 20151019 | 21 | Chrome | 39.0.2171.71 | 1024x768 | desktop | 1 |
+-----------+-------+------------+-----------------+-------------+----------+-----------------+
18 rows selected (2.086 seconds)
While it’s definitely possible to interface with the data this way, Apache Drill offers an alternative solution in the form of custom user defined functions. In my next post, I’ll show you how to implement a GAHELPER() function that makes working with Google Analytics data from the Drill command line significantly easier.