Old and busted: Teasing formerly-fashionable websites from Reddit data
Anyone who spends even a little bit of time on the Internet knows how fickle and volatile the cultural scene is. And there’s perhaps no greater exemplar of this volatility than Reddit. For good or bad, Reddit communities often serve as tastemakers for the Internet at large. If your content is visible on Reddit, chances are that things are going great for you. And if not, well, maybe not…
The topic for today’s post is pretty simple—I’m just going to show off a cool analysis related to this observation. The data set will be a JSON dump of all Reddit submissions from 2006 up through Summer 2015, which I’ll be analyzing for site URLs that used to be popular but have recently fallen out of favor. The size of this dump was fairly formidable (about a quarter-terabyte uncompressed), so on the backend this analysis was facilitated by running Drill in a cluster configuration on a Hadoop filesystem. This kept the runtime of the somewhat sophisticated query I needed to perform down to well under an hour.
So how exactly does one go about determining which Reddit submission URLs are, technically speaking, “old and busted”? Well, I started off my analysis by constructing a view to keep track of the relevant parameters and convert them to the correct format and units. In my case I’m interested the number of times a URL shows up in a submission, the average posting date for each URL, and the standard deviation in submission dates (in units of days):
CREATE VIEW reddit AS SELECT domain, COUNT(domain) counts, TO_TIMESTAMP(avg(CAST(created_utc AS FLOAT))) avg_date, STDDEV(CAST(created_utc AS FLOAT))/86400 std_dev_days
FROM hdfs.`/data/RS_full_corpus.json`
GROUP BY domain;
So now it becomes fairly easy to construct a query on top of this view that looks for websites with old average submission dates that also exhibit fairly strongly clustering (which I’ll define as an average submission date older than Jan. 1, 2011 with a standard deviation in submission dates of less than 600 days). These two in combination will define our “old and busted” criterion.
The query looks like this, and returns these results:
> SELECT * FROM reddit WHERE std_dev_days < 600 AND avg_date < '2011-01-01 00:00:00' ORDER BY counts DESC LIMIT 20;
+------------------------+---------+--------------------------+---------------------+
| domain | counts | avg_date | std_dev_days |
+------------------------+---------+--------------------------+---------------------+
| self.reddit.com | 647870 | 2010-09-02 13:56:28.448 | 301.71035168793304 |
| examiner.com | 151810 | 2010-12-16 23:26:30.526 | 585.7963478654447 |
| news.bbc.co.uk | 88227 | 2009-10-19 22:09:54.047 | 499.8828691832385 |
| squidoo.com | 68613 | 2010-02-15 05:45:45.863 | 457.7467960677672 |
| hubpages.com | 57290 | 2010-01-30 02:18:28.314 | 353.1463760830986 |
| msnbc.msn.com | 43643 | 2010-06-13 13:34:33.274 | 491.4442681051865 |
| associatedcontent.com | 24146 | 2009-08-18 17:40:57.408 | 403.1500022424656 |
| tinyurl.com | 24070 | 2010-08-28 15:11:38.083 | 471.1292710623187 |
| self.programming | 20689 | 2009-11-08 14:04:07.185 | 239.53706245104482 |
| physorg.com | 17431 | 2010-09-27 02:00:58.908 | 435.832257804899 |
| ehow.com | 16228 | 2009-09-19 05:58:19.334 | 524.9960557567199 |
| gather.com | 15387 | 2010-06-28 12:05:28.479 | 365.76299060306405 |
| english.aljazeera.net | 14573 | 2010-10-02 14:05:55.813 | 360.5432415872375 |
| subimg.net | 13459 | 2010-09-29 09:48:42.801 | 278.7920245425415 |
| helium.com | 13337 | 2009-09-28 16:38:56.651 | 441.641404727207 |
| sports.espn.go.com | 12416 | 2010-10-17 19:30:23.67 | 493.84151020454976 |
| rapidsharelist.net | 12128 | 2010-04-26 15:53:44.063 | 14.947036935681274 |
| waronyou.com | 12036 | 2009-04-13 17:51:18.434 | 184.16688348655214 |
| timesonline.co.uk | 11100 | 2009-05-09 01:23:30.756 | 288.42826940864705 |
| open.salon.com | 10727 | 2010-08-10 09:48:09.563 | 494.63567877466306 |
+------------------------+---------+--------------------------+---------------------+
20 rows selected (2490.628 seconds)
Using this list as a starting point, I started to do a little digging (see Table 1) into why these sites are no longer popular. What I found is that there a lot of reasons a site may end up in this ignominious category—anything from a shift in the Google search algorithm to a simple redirect to a new URL. Other explanations included acquisition, a collapsed business model, and an outright ban of the URL from Reddit by site administrators.
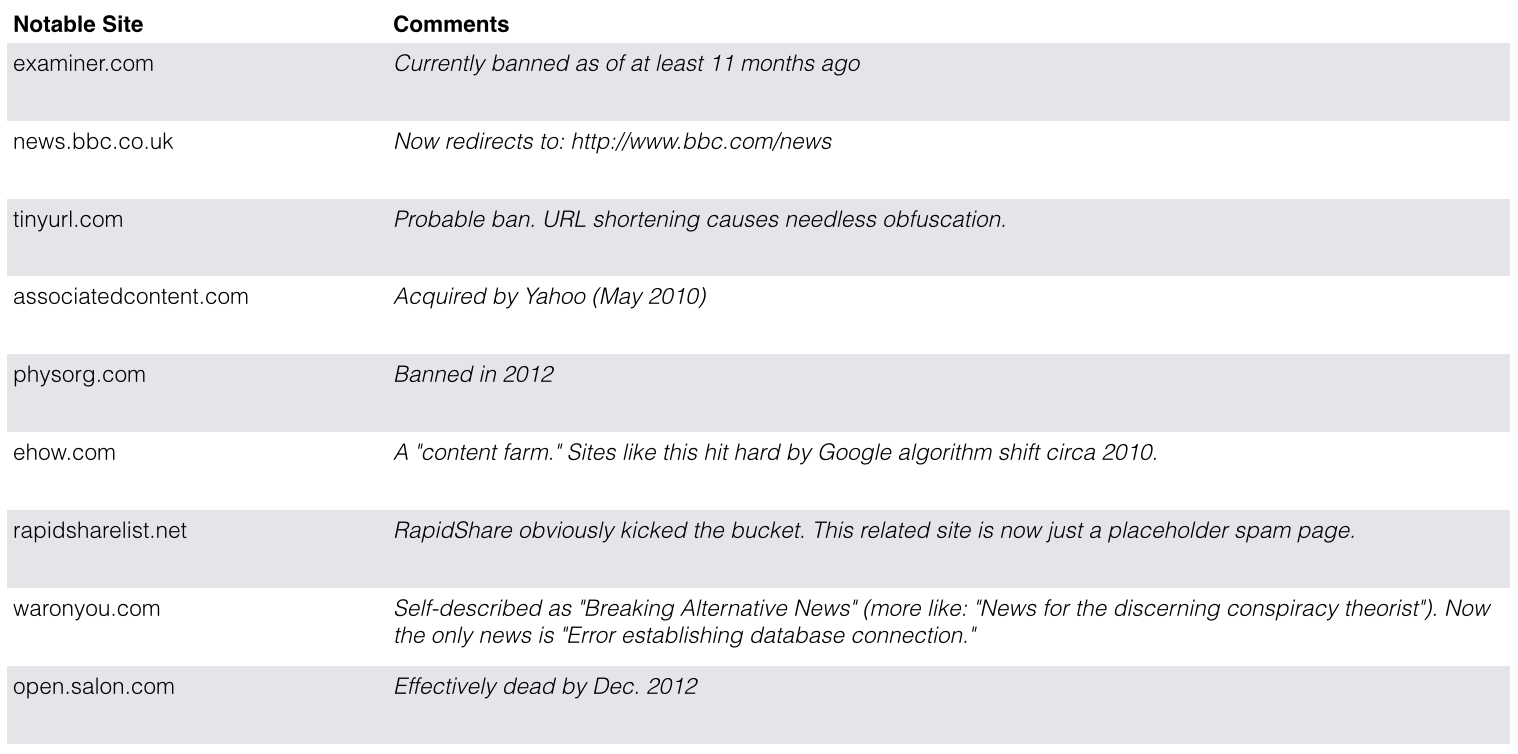
Table 1: A selection of formerly-fashionable websites submitted to Reddit, and the suspected reason for their fall from grace.
This is pretty interesting stuff, right? I’m definitely looking forward to using Drill to hunt for even more trends in the Reddit submission data.